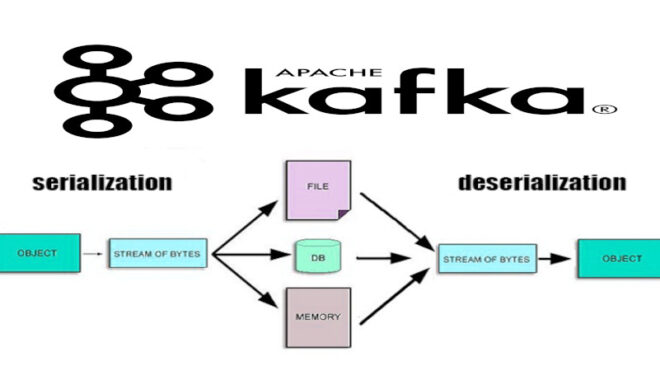
Apache Kafka — это распределенная платформа для обработки и передачи потоков данных в реальном времени. Одной из ключевых концепций в Kafka является сериализация данных. Сериализация — это процесс преобразования объекта в поток байтов, который может быть легко передан по сети или сохранен в хранилище данных. Сериализация в Apache Kafka предоставляет несколько важных преимуществ, которые существенно облегчают обмен данными в рамках этой распределенной системы обработки потоков данных[1]:
- Передача объектов через сеть: когда вы отправляете сообщение в Kafka, оно должно быть представлено в виде потока байтов. Сериализация позволяет преобразовывать сложные объекты в последовательность байтов, которую можно безопасно передавать через сеть.
- Поддержка различных форматов данных: Kafka позволяет использовать различные форматы данных в сообщениях. Вместо ограничения только строками, вы можете использовать JSON, Avro, Protobuf и другие форматы данных, которые соответствуют вашим потребностям. Сериализация делает это возможным.
- Унификация обмена данными между разными языками программирования: Когда различные компоненты системы используют разные языки программирования, сериализация позволяет им обмениваться данными в стандартизированном формате. Это особенно важно в микросервисных архитектурах, где различные службы могут быть написаны на разных языках.
- Эффективное хранение данных: При хранении данных в топиках Kafka сериализация позволяет представить их в формате, который эффективно использует ресурсы хранилища. Это особенно важно в сценариях с большим объемом данных.
- Поддержка эволюции схем данных: Некоторые форматы сериализации, такие как Avro и Protobuf, предоставляют поддержку эволюции схем данных. Это означает, что вы можете вносить изменения в структуру данных, не нарушая совместимость с предыдущими версиями кода.
Сериализация в Kafka: особенности работы
Kогда вы отправляете сообщение в Kafka, оно должно быть представлено в виде потока байтов. Сериализация позволяет нам преобразовать объекты в байтовый формат для передачи их через топики Kafka. При получении сообщения из топика, оно десериализуется обратно в объект для обработки. Рассмотрим примеры использования сериализации в Kafka с помощью библиотеки Apache Kafka и языка программирования Java [2]:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Properties;
public class KafkaSerializationExample {
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String TOPIC_NAME = "example-topic";
public static void main(String[] args) {
Properties producerProps = new Properties();
producerProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
producerProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producerProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProps);
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "key", "Hello, Kafka!");
producer.send(record);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> consumerRecord : records) {
System.out.printf("Consumed record with key %s and value %s%n", consumerRecord.key(), consumerRecord.value());
}
producer.close();
consumer.close();
}
}
В этом примере мы использовали StringSerializer и StringDeserializer для сериализации и десериализации сообщений в формате строк. Также стоит отметить, что при сериализации и десериализации необходимо правильно выставить настройки в конфигурации объекта свойств Properties.
Для более сложных объектов, таких как Java объекты, мы можем использовать JSON-сериализацию, предварительно настроив ее под свои нужды:
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.Serializer;
import java.io.IOException;
import java.util.Map;
public class JsonSerializer<T> implements Serializer<T>, Deserializer<T> {
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public byte[] serialize(String topic, T data) {
try {
return objectMapper.writeValueAsBytes(data);
} catch (IOException e) {
throw new RuntimeException("Error serializing object", e);
}
}
@Override
public T deserialize(String topic, byte[] data) {
try {
return objectMapper.readValue(data, objectType());
} catch (IOException e) {
throw new RuntimeException("Error deserializing object", e);
}
}
protected Class<T> objectType() {
// Замените на конкретный тип объекта, который вы ожидаете
return (Class<T>) Object.class;
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public void close() {
}
}
Теперь мы можем использовать наш JsonSerializer вместо StringSerializer для работы с объектами:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaJsonSerializationExample {
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String TOPIC_NAME = "json-example-topic";
public static void main(String[] args) {
Properties producerProps = new Properties();
producerProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
producerProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producerProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class.getName());
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonSerializer.class.getName());
KafkaProducer<String, User> producer = new KafkaProducer<>(producerProps);
User user = new User("John Doe", 25);
ProducerRecord<String, User> record = new ProducerRecord<>(TOPIC_NAME, "key", user);
producer.send(record);
KafkaConsumer<String, User> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
ConsumerRecords<String, User> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, User> consumerRecord : records) {
System.out.printf("Consumed record with key %s and value %s%n", consumerRecord.key(), consumerRecord.value());
}
producer.close();
consumer.close();
}
}
Как видно из вышеприведенного фрагмента кода, мы использовали наш предварительно настроенный JsonSerializer для сериализации сложных объектов.
Таким образом, сериализация в Kafka играет ключевую роль в обеспечении эффективного, гибкого и стандартизированного обмена данными между компонентами системы обработки потоков данных.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800 руб.
Это делает Apache Kafka надежным и универсальным средством для хранения и обмена большими потоками данных, что активно применяется в задачах Data Science и разработке распределенных приложений.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- https://kafka.apache.org/documentation/#consumerconfigs
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

